

Superman demeure mon super-héros préféré. Sous l’air timide de Clark Kent, celui-ci cache une force et une résistance à toute épreuve. Mais voilà que les biologistes sont en train de construire Supercellule, qui promet des prouesses tout aussi extraordinaires.
Ce qui suit est inspiré d’un article se Scientific American de juillet 2019: The Invulnerable Cell, par Rowan Jacobsen. Je vais m’efforcer de simplifier la biologie pour mettre l’emphase sur la logique du processus.
Lorsque j’étais étudiant en biochimie dans les années 70, une question typique d’examen pouvait se résumer ainsi: « Décrivez une expérience permettant de déterminer si le processus X dans une cellule est dépendant du processus Y ». Il nous suffisait alors d’utiliser notre connaissance des processus X et Y et des technologies permettant d’affecter ces processus (l’objet de notre cours de biochimie) pour planifier une expérience permettant de répondre à la question. Les technologies ont beaucoup évolué depuis les années 70, ce qui permet maintenant de répondre à la question suivante:
Décrivez une expérience permettant de créer des cellules résistantes à tout virus.
Non seulement on a pu planifier une telle approche, mais on est en train de réaliser l’expérience, un projet de longue haleine étant donné le nombre de manipulations génétiques nécessaires. La beauté de cette expérience réside dans la logique ingénieuse utilisée pour attaquer le problème. Tous les éléments étaient déjà connus dans les années 70, mais la technologie nécessaire n’était pas encore disponible. Allons-y étape par étape.
La cellule
La cellule est l’unité de vie. Celle-ci est constituée d’une membrane qui enveloppe la machinerie nécessaire aux fonctions de la vie: gestion de l’énergie, construction/réparation à partir de matières premières, gestion des déchets, reproduction.
Les bactéries sont constitués d’une seule cellule. Les organismes plus avancés (plantes, animaux, humains) peuvent contenir des milliards de cellules spécialisées, qui travaillent de concert en vue de maintenir l’organisme en vie.
Pensez à votre demeure. Les murs (la membrane) sont une barrière permettant de maintenir un environnement intérieur différent de l’environnement extérieur. Les ouvertures dans les murs (portes, fenêtres, entrée d’eau et d’électricité, etc.) permettent de contrôler ce qui entre et ce qui sort, le rôle de la membrane dans une cellule.
Mais la cellule est beaucoup plus complexe que votre demeure. Celle-ci peut se reproduire. Elle contient les plans de sa propre construction, sous forme d’ADN, ainsi que la machinerie nécessaire pour construire un duplicata. Imaginez votre demeure contenant les plans de la maison, ainsi que les corps de métier nécessaire à sa reconstruction!
Le virus
Un virus est minuscule, comparé à une cellule. Ce n’est qu’une enveloppe de protéines contenant les plans de sa propre construction, sous forme d’ADN (ou ARN). Chaque virus a une affinité spécifique pour un type de cellule en particulier. Il s’attache à la membrane de cette cellule et injecte les plans de sa propre construction (ADN) à l’intérieur de la cellule. La machinerie de la cellule lit ces plans et se met à fabriquer des virus, jusqu’à ce que la cellule éclate, bourrée de virus.
Les protéines
Les protéines jouent un rôle primordial dans notre histoire. Celles-ci ont d’abord une fonction structurale. Votre foie, vos cheveux, votre peau et autres organes sont constitués en grande partie de protéines. La cellule elle-même maintient sa forme à l’aide de protéines.
Un autre rôle primordial des protéines, parmi plusieurs autres, est celui d’enzyme. Les enzymes sont les fameux corps de métier qui permettent à la machinerie cellulaire d’opérer. Chaque enzyme est spécialisé dans une seule fonction biochimique, consistant à lier ensemble des éléments simples ou, au contraire, à briser des liens existants, libérant ou utilisant de l’énergie dans le processus. Les enzymes sont les chimistes de la cellule.
Les protéines tirent leur polyvalence de leur structure. Ils sont constitués de 20 types de molécules, appelés acides aminés, mis bout à bout dans un ordre spécifique et unique à chaque protéine (généralement plus d’une centaine). Les acides aminés ont des structures et propriétés chimique différentes, souvent déterminées par leur affinité pour l’eau, le gras et l’acidité. La composition exacte d’une protéine détermine sa structure tridimensionnelle, ses propriétés structurelles, ainsi que son activité enzymatique.
L’ADN
L’ADN d’une cellule contient les plans de construction et d’opération de la cellule. Celui-ci est constitué d’une série de « nucléotides », chacun comprenant un de quatre types de molécules, appelés bases azotés. Les bases azotés sont souvent représenté par les quatre lettres suivantes: A, C, G, T. Les nucléotides sont mis bout à bout dans un ordre spécifique et unique à l’organisme concerné. Le génome humain en contient quelques milliards.
La séquence de bases azotées dans une partie de l’ADN (les gènes) constitue un code pour la fabrication des protéines (voir une prochaine section). Une grande partie de l’ADN sert par contre à contrôler l’expression de ces gènes. Ce contrôle s’exerce souvent à l’aide de protéines qui se lient à ces sections régulatrices.
NOTE: l’ADN est constitué de deux chaines de nucléotides complémentaires (la double hélice). Nous n’avons pas à considérer ceci pour la présente discussion.
L’ARN
L’ARN constitue un intermédiaire entre l’ADN et le site de fabrication des protéines. Des sections d’ADN dont l’organisme a besoin sont copiés sous forme d’ARN. L’ARN a une composition similaire à l’ADN, et peut donc transporter l’information codée par l’ADN en maintenant son intégrité. Les nucléotides de l’ARN sont désignés par les lettres A, C, G, U.
Nous sommes intéressés par deux types d’ARN, fabriqués à partir de différents endroits de l’ADN:
- L’ARN messager, qui code pour la fabrication de protéines en spécifiant les acides aminés qui seront nécessaires (voir code génétique)
- L’ARN de transfert, non-codant, fabriqué en diverses variétés, chacune pouvant se lier à un acide aminé spécifique et l’amener au site de fabrication des protéines (un ribosome) pout y être intégré lorsque l’ARN messager le demande.
Le code génétique
Le code génétique réfère à la séquence de « lettres » dans l’ARN messager qui, lue trois lettres à la fois, se traduit par le choix d’un acide aminé spécifique à insérer dans la chaine formant une protéine. C’est l’ARN de transfert qui transporte cet acide aminé au site de fabrication du ribosome.
Comme nous avons 4 lettres et que le code requiert des séries de 3 lettres, il est possible de former 64 différentes séries de trois lettres. Ces groupes sont appelés CODONS. Nous avons 64 codons pour coder 20 acides aminés. Il y a un surplus, et c’est là le secret de la réponse à notre question initiale: le même acide aminé peut être codé par plusieurs (1 à 6) différents codons. Voir le tableau suivant, où les 20 acides aminés apparaissent dans la première colonne, et les codons correspondants dans les rangées adjacentes.
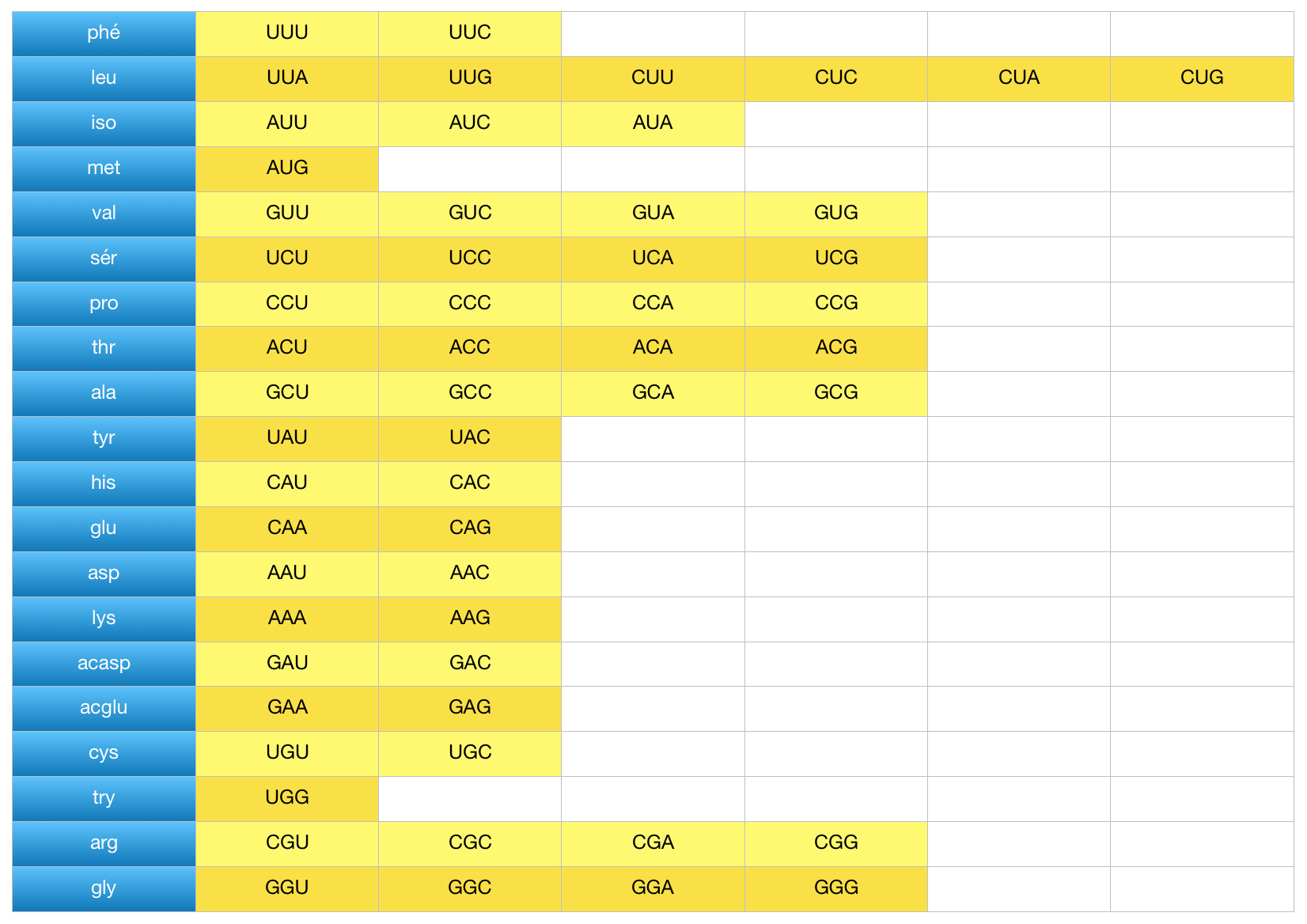
NOTE: les codons UAA, UAG, UGA marquent la fin de la chaine à construire. Ce sont des codons STOP.
Récapitulons avec un exemple:
- Une section de l’ADN correspondant à un gène est lue et transcrite sous form d’ARN messager, qui se rend sur le site de construction des protéines (le ribosome). Supposons qu’une section de l’ARN messager contient la séquence suivante: GUCACACUCUAA.
- La série est interprétée 3 lettres à la fois: GUC-ACA-CUC-UAA. Le tableau ci-haut nous permet de déterminer que les acides aminés à ajouter à la protéine en construction sont: val-thr-leu-STOP.
- La lecture de l’ADN a aussi produit divers ARN de transfert, non codant, qui se sont associés à divers acides aminés spécifiques. Certains sont associés aux acides aminés val, thr et leu, dont on a besoin. L’ARN de transfert comporte une section qui reconnait un codon particulier sur l’ARN messager, au site de construction des protéines.
- Le site de construction d’une protéine est très complexe. Dans ce cas, parce que l’ARN messager demande un val, seul l’ARN de transfert spécifiquement attaché à l’acide aminé val se joint au complexe et l’acide aminé est ajouté à la protéine en construction.
- La construction de la protéine se poursuit, cette fois avec l’acide aminé thr, puis leu. Le codon STOP signifie que la construction de la protéine est terminée.
Une pause youtube permet de voir le processus discuté jusqu’à maintenant (en anglais):
Manipulation génétique
La technologie permet maintenant de remplacer des sections d’ADN dans une cellule vivante par des sections manufacturées en industrie. Il est possible de simplement commander de telles sections, sur mesure, jusqu’à 4000 lettres de longueur. Le code génétique complet de certaines bactéries, dont E. coli, est aussi connu.
Nous avons maintenant tout ce qu’il faut pour notre expérience avec la bactérie E.coli. Voici les étapes:
- Entrer le code génétique connu (la séquence de codons) de la bactérie dans un programme de traitement texte.
- Choisir un acide aminé pour lequel il existe plusieurs codons permettant de le coder.
- Choisir un des codons identifiés au point 2, et remplacer par un codon qui code pour le même acide aminé. Ce remplacement est fait partout (ou si possible dans les gènes codant pour des protéines). En théorie, notre programme de traitement de texte contient maintenant un code génétique valide pour la bactérie, mais dont un codon en particulier est absent.
- Couper des sections de ce texte en parties plus petite et commander de l’ADN à l’industrie (sections de 4000 bases ou moins).
- Introduiser graduellement les sections dans la bactérie, remplaçant les sections correspondantes existantes. Ceci est un long processus. On doit permettre aux bactéries de se multiplier après chacune des opérations de remplacement et on doit régler certains problèmes (par exemple, si on a remplacé un codon dans une section de contrôle non-codante de l’ADN, il se peut que le remplacement ne fasse pas l’affaire).
- Éliminer de la bactérie l’ADN qui code spécifiquement pour l’ARN de transfert qui reconnait le codon qu’on a éliminé. Cet ARN de transfert est inutile à la bactérie de toute façon, puisque la nouvelle bactérie créée ne fabriquera pas d’ARN messager contenant ce codon.
Conclusion
Après cette procédure, la bactérie continue de fonctionner normalement, mais un problème se pose pour tout virus l’attaquant. L’ADN du virus injecté dans la cellule contient les gènes nécessaires à la fabrication de celui-ci. Ces gènes contiennent tous le code permettant de créer de l’ARN messager contenant le codon qu’on a éliminé de la bactérie. Mais comme on a aussi éliminé l’ARN de transfert correspondant à ce codon, l’acide aminé nécessaire ne peut être transporté sur le site de construction des protéines. L’ADN du virus ne peut mener à la construction de protéines, donc le virus ne peut se reproduire. On a une Supercellule!
Une telle bactérie résistante aux virus pourrait être utilisée dans l’industrie alimentaire ou pharmaceutique, où on utilise déjà des bactéries. Et dans un futur lointain, pourrait-on penser devenir nous même résistants aux virus?
